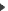 ")) {
tester_variable('puce_rtl', "
")) {
tester_variable('puce_rtl', "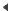 ");
}
//
// Diverses fonctions essentielles
//
// Ne pas afficher le chapo si article virtuel
function nettoyer_chapo($chapo){
if (substr($chapo,0,1) == "="){
$chapo = "";
}
return $chapo;
}
// points d'entree de pre- et post-traitement pour propre() et typo()
function spip_avant_propre ($letexte) {
$letexte = avant_propre_ancres($letexte);
$letexte = extraire_multi($letexte);
if (function_exists('avant_propre'))
$letexte = avant_propre($letexte);
return $letexte;
}
function spip_apres_propre ($letexte) {
if (function_exists('apres_propre'))
$letexte = apres_propre($letexte);
return $letexte;
}
function spip_avant_typo ($letexte) {
$letexte = extraire_multi($letexte);
$letexte = avant_typo_smallcaps($letexte);
if (function_exists('avant_typo'))
$letexte = avant_typo($letexte);
return $letexte;
}
function spip_apres_typo ($letexte) {
// relecture des
if (!_DIR_RESTREINT AND $GLOBALS['revision_nbsp'])
$letexte = str_replace(' ',
' ', $letexte);
if (function_exists('apres_typo'))
$letexte = apres_typo($letexte);
return $letexte;
}
//
// Mise de cote des echappements
//
// Definition de la regexp de echappe_html
define ('__regexp_echappe',
"/(" . "((.*?))<\/html>" . ")|(" #html
. "
");
}
//
// Diverses fonctions essentielles
//
// Ne pas afficher le chapo si article virtuel
function nettoyer_chapo($chapo){
if (substr($chapo,0,1) == "="){
$chapo = "";
}
return $chapo;
}
// points d'entree de pre- et post-traitement pour propre() et typo()
function spip_avant_propre ($letexte) {
$letexte = avant_propre_ancres($letexte);
$letexte = extraire_multi($letexte);
if (function_exists('avant_propre'))
$letexte = avant_propre($letexte);
return $letexte;
}
function spip_apres_propre ($letexte) {
if (function_exists('apres_propre'))
$letexte = apres_propre($letexte);
return $letexte;
}
function spip_avant_typo ($letexte) {
$letexte = extraire_multi($letexte);
$letexte = avant_typo_smallcaps($letexte);
if (function_exists('avant_typo'))
$letexte = avant_typo($letexte);
return $letexte;
}
function spip_apres_typo ($letexte) {
// relecture des
if (!_DIR_RESTREINT AND $GLOBALS['revision_nbsp'])
$letexte = str_replace(' ',
' ', $letexte);
if (function_exists('apres_typo'))
$letexte = apres_typo($letexte);
return $letexte;
}
//
// Mise de cote des echappements
//
// Definition de la regexp de echappe_html
define ('__regexp_echappe',
"/(" . "((.*?))<\/html>" . ")|(" #html
. "((.*?))<\/code>" . ")|(" #code
. "<(cadre|frame)>((.*?))<\/(cadre|frame)>" #cadre
. ")|("
. "<(poesie|poetry)>((.*?))<\/(poesie|poetry)>" #poesie
. ")/si");
define('__preg_img', ',<(img|doc|emb)([0-9]+)(\|([^>]*))?'.'>,i');
function echappe_html($letexte, $source='SOURCEPROPRE', $no_transform=false) {
if (preg_match_all(__regexp_echappe, $letexte, $matches, PREG_SET_ORDER))
foreach ($matches as $regs) {
$num_echap++;
$marqueur_echap = "@@SPIP_$source$num_echap@@";
if ($no_transform) { // echappements bruts
$les_echap[$num_echap] = $regs[0];
}
else
if ($regs[1]) {
// Echapper les ...
$les_echap[$num_echap] = $regs[2];
}
else
if ($regs[4]) {
// Echapper les ...
$lecode = entites_html($regs[5]);
// supprimer les sauts de ligne debut/fin (mais pas les espaces => ascii art).
$lecode = ereg_replace("^\n+|\n+$", "", $lecode);
// ne pas mettre le s'il n'y a qu'une ligne
if (is_int(strpos($lecode,"\n"))) {
$lecode = nl2br("".$lecode."");
$marqueur_echap = "$marqueur_echap";
} else
$lecode = "".$lecode."";
$lecode = str_replace("\t", " ", $lecode);
$lecode = str_replace(" ", " ", $lecode);
$les_echap[$num_echap] = $lecode;
}
else
if ($regs[7]) {
// Echapper les ...
$lecode = trim(entites_html($regs[9]));
$total_lignes = substr_count($lecode, "\n");
$les_echap[$num_echap] = "";
// Les marques ci-dessous indiquent qu'on ne veut pas paragrapher
$marqueur_echap = "\n\n $marqueur_echap\n\n";
}
else
if ($regs[12]) {
$lecode = $regs[14];
$lecode = ereg_replace("\n[[:space:]]*\n", "\n \n",$lecode);
$lecode = str_replace("\r", "\n", $lecode); # gestion des \r a revoir !
$lecode = "".ereg_replace("\n+", "\n", $lecode)."";
$marqueur_echap = "\n\n $marqueur_echap\n\n";
$les_echap[$num_echap] = propre($lecode);
}
$letexte = str_replace($regs[0], $marqueur_echap, $letexte);
}
// Gestion du TeX
if (!(strpos($letexte, "